![Как увеличить видимость сайта в Яндексе на 39% за месяц [кейс PromoPult]](https://blog.promopult.ru/wp-content/uploads/2022/11/обложка-в-блог-4.png)
SEO: поиск и внутренняя оптимизация
Как увеличить видимость сайта в Яндексе на 39% за месяц [кейс PromoPult]
Результаты продвижения сайта строительной компании в SEO-модуле PromoPult

Особенности применения, проверка и решения для WordPress
Noindex и nofollow — разные по функционалу элементы. Их часто путают, и как только не называют: тегами, метатегами, атрибутами. Расставим все точки над «i» и расскажем, чем отличается noindex от nofollow и в каких случаях их целесообразно использовать.
Прежде всего, noindex и nofollow (наряду с index и follow) — это указания для поисковых роботов в метатегах секции
. Их понимают все без исключения поисковики. Указания index или noindex разрешают или запрещают роботу индексировать содержимое страницы, а follow и nofollow — переходить по ссылкам на странице.Возможны такие варианты:
<meta name="robots" content="index, follow"/>— в этом случае разрешена индексация страницы и ссылок.
<meta name="robots" content="noindex, follow"/>— запрещена индексация содержимого страницы, но разрешен переход по ссылкам.
<meta name="robots" content="index, nofollow"/>— разрешена индексация, но запрещен переход по ссылкам.
<meta name="robots" content="noindex, nofollow"/>— запрещается и индексация, и переход по ссылкам.
От индексации следует закрывать служебные страницы (вход в административную панель, логи сервера) а также дублированный контент (страницы архивов, тегов, результаты поиска по сайту, в некоторых случаях — пагинацию).
Если вы хотите оставить указания только для какого-то конкретного робота, нужно указать его идентификатор в метатеге. Например, для бота Google:
<meta name="googlebot" content="noindex, follow"/>Если не задать указания для робота, то он по умолчанию принимает значения index и follow.
Перечень метатегов, которые учитывает Яндекс, найдете в Справке Вебмастера, Google — в документации Центра Google поиска.
Запретить поисковым роботам индексировать страницу можно несколькими способами. Самых популярных два:
<meta name="robots" content="noindex, nofollow"/>Запретить страницу для индексации при помощи директивы Disallow в файле robots.txt:
Disallow: /page1.htmlВ чем же принципиальная разница между этими двумя методами?
Для страниц, которые еще не проиндексированы роботами, особой разницы нет — можно использовать оба способа.
Страницы, которые уже есть в индексе, лучше закрывать директивами noindex и nofollow в meta robots. В этом случае поисковики быстрее исключат страницу их индекса и больше не проиндексируют ее.
Важно! Чтобы робот правильно интерпретировал директивы noindex и nofollow и не добавил страницу в индекс, нельзя одновременно закрывать доступ к ней в файле robots.txt при помощи директивы Disallow. Робот не получает доступа к странице и не видит запрещающих директив. А если на страницу стоит ссылка с другого сайта, краулер перейдет по ней и добавит страницу в индекс.
Еще один вариант полного запрета индексации страницы — настроить HTTP-ответ с заголовком X-Robots-Tag и значением noindex или none. Пример такого заголовка в коде:
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
X-Robots-Tag: noindexДля того чтобы закрыть не всю страницу, а только ее часть от индексации, используется тег <noindex>. Причем это «ноу-хау» Яндекса. Google тег не понимает и считает его невалидным. Синтаксис выглядит так:
<noindex>текст, который следует скрыть от индексации</noindex>Проблема в том, что при такой конструкции во время валидации кода будут ошибки. Если вы хотите сделать код валидным, используйте такой синтаксис:
<!--noindex-->текст, который следует скрыть от индексации<!--/noindex-->Альтернативный способ закрыть от индексации часть текста на странице — добавить тег <noscript>. В коде это будет выглядеть так:
<noscript>текст, который следует скрыть от индексации</noscript>Тег <noscript> запрещает индексацию и дополнительно скрывает содержимое от пользователя, браузер которого поддерживает JavaScript. Эта технология поддерживается всеми популярными браузерами, но может быть отключена самим пользователем.
Скрывать от индексации есть смысл:
По поводу тега <noindex> есть заблуждение. Считается, что текст, помещенный в него, Яндекс вообще не учитывает. Это не так. Яндекс читает его и принимает во внимание при определении релевантности страницы и ее уникальности, просто он не добавляет его в индексную базу.
Изначально nofollow использовали только в метатеге на уровне страницы. Но со временем возникла острая необходимость закрывать не все ссылки на странице от индексации, а только некоторые из них. Так появился атрибут rel="nofollow" тега <а>. Он относится только к ссылке, для которой указан. Синтаксис выглядит так:
<a href="index.php" rel="nofollow">Перейти</a>Чтобы запретить поисковым роботам переходить по всем ссылкам (и внешним, и внутренним) на уровне страницы, используйте директиву "nofollow" в meta robots.
Некоторые пытаются закрывать ссылки от индексации, используя тег <nofollow>. Выглядит это таким образом:
<nofollow><a href="index.php">Перейти</a></nofollow>Это неверно.
Запомните, что тега <nofollow> для того, чтобы закрыть от индексации ссылку, не существует — только атрибут rel или директива в meta robots со значением nofollow.
Более распространенная ошибка — попытка закрыть ссылку от индексации с помощью тега <noindex>. В этом случае будет закрыт только анкор и только для Яндекса. По ссылке же роботы смогут переходить.
Закрывают ссылки атрибутом nofollow в таких случаях:
Google предоставляет вебмастерам возможность более точно описать ссылки, которые содержатся на странице. Сделать это можно при помощи таких значений атрибута rel:
<a href="example.com" rel="ugc,nofollow">Перейти</a>На страницах сайта зачастую расположено много служебных элементов, которые нет смысла индексировать. Их закрывают с помощью тега <noindex>. Прежде всего, это счетчики (Liveinternet, Яндекс.Метрика, Google Аналитика и т. п.), различные информеры, блоки оформления подписки и т. п.
Пример в коде сайта Wildberries:
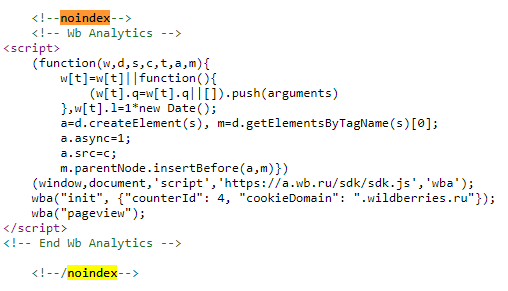
А вот блоки рекламы (например, от РСЯ) закрывать не нужно.
Для сайтов на системе управления WordPress большинство задач по закрытию от индексации отдельных страниц или их типов можно решить при помощи плагинов.
Самые популярные:
В разделе «Общие настройки» плагина All in One SEO Pack есть возможность закрыть от индексации служебные и не нужные в индексе страницы:
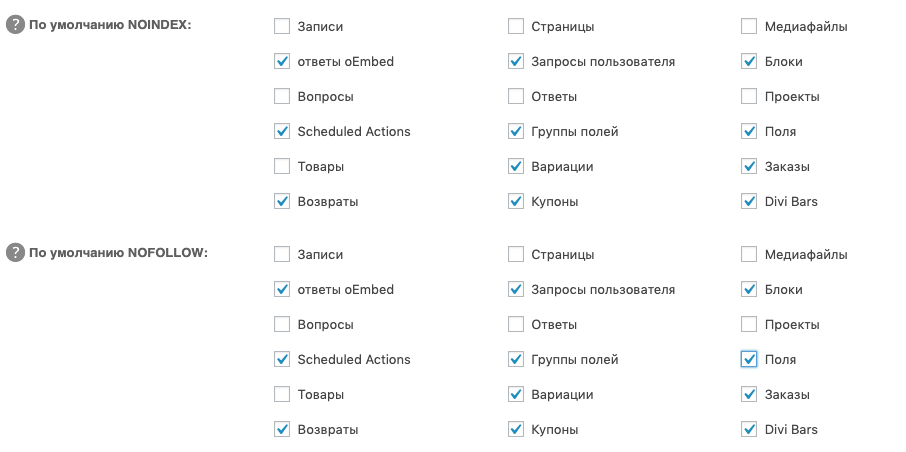
А также — рубрики, архивы, страницу поиска и 404:

А еще — категории, метки, теги, рубрики и при необходимости страницы с пагинацией:
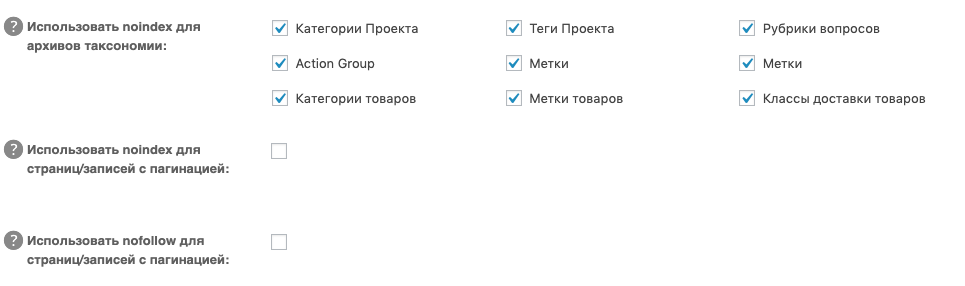
Эти настройки позволяют гибко управлять сканированием сайта, не расходовать краулинговый бюджет и избегать дублей и «мусорных» страниц в индексе.
Конечно, можно найти эти элементы в режиме просмотра кода, если требуется информация для одной страницы. Но ручная проверка даже небольшого многостраничного ресурса неэффективна.
Расскажем о двух способах найти noindex и nofollow на сайте.
Какие атрибуты и теги использованы на страницах сайта, наглядно покажет бесплатное расширение для браузера RDS Bar. Оно доступно для Chrome, Opera и Firefox.
После установки активируйте расширение, кликнув на значок:

В настройках в разделе «Подстановка» можно отметить, какие именно элементы следует подсвечивать на странице:
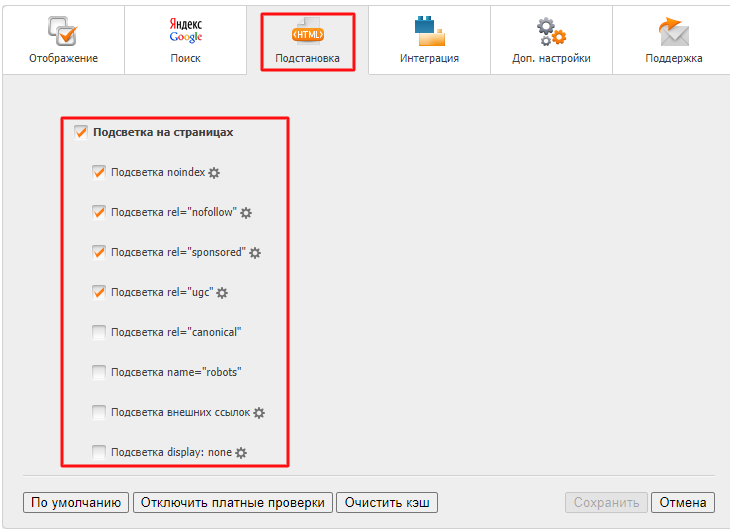
После этого ссылки с rel="nofollow" будут отображаться как перечеркнутые:

А контент, не подлежащий индексированию, будет выделяться другим цветом:

Не только узнать, есть ли noindex и nofollow на сайте, но и проверить, правильно ли они использованы, можно в SEO-модуле PromoPult. На шаге создания проекта «Целевые страницы» можно провести быстрый анализ технической оптимизации страниц. Проверка происходит бесплатно и занимает несколько секунд.
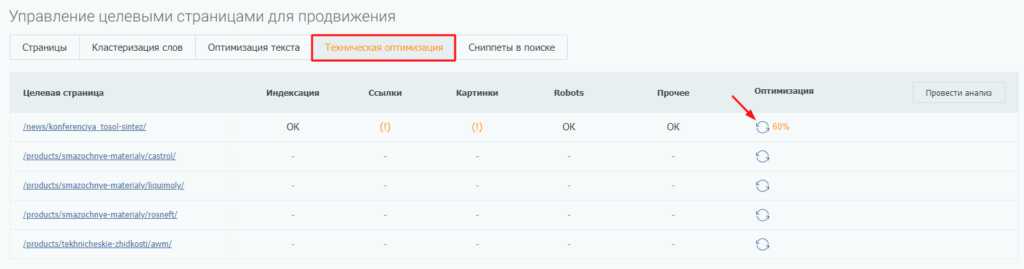
Восклицательные знаки в таблице обозначают проблему. Если нажать на знак, раскроется подробное описание параметров страницы:
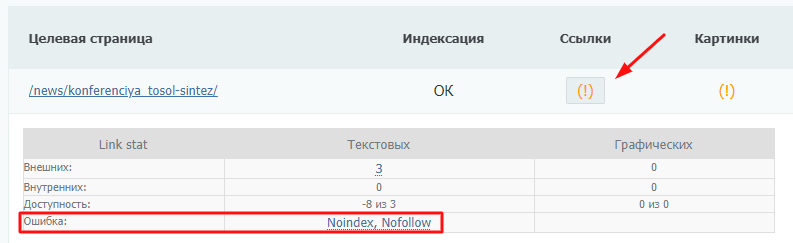
Наличие запретов в robots можно посмотреть в колонке «Прочее»:
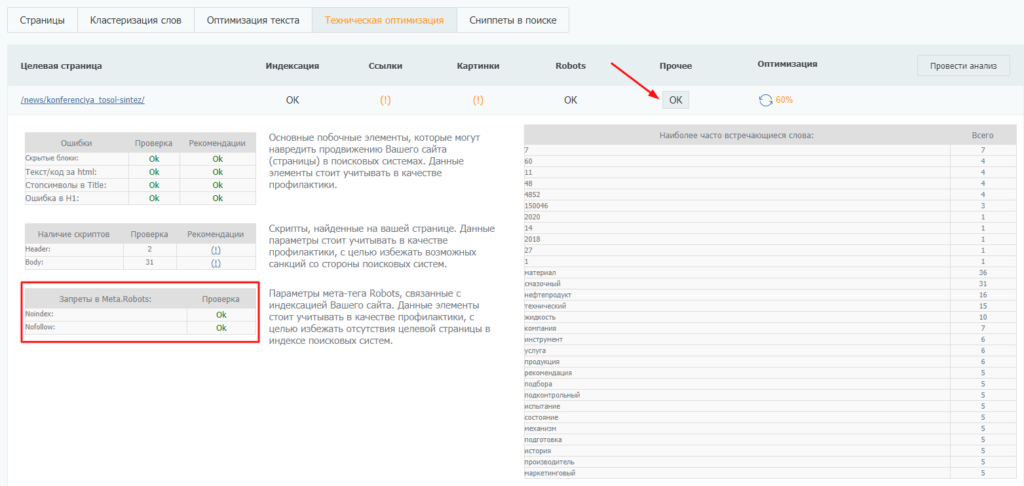
После проверки можете самостоятельно исправить ошибки и запустить повторную проверку, а можете доверить оптимизацию специалистам PromoPult.
Некоторые оптимизаторы в погоне за сохранением драгоценного веса закрывают с помощью noindex и nofollow все, что только можно, не оставляя ни одной внешней ссылки. Это ошибка. Дело в том, что ссылки на авторитетные ресурсы поднимают рейтинг вашего сайта в глазах поисковиков. Не бойтесь ссылаться — это вполне нормально, если вы указываете источники данных и полезные ресурсы.
Результаты продвижения сайта строительной компании в SEO-модуле PromoPult
![Увеличили переходы из поиска в 6 раз и конверсии в 5 раз за полмесяца [кейс PromoPult]](https://blog.promopult.ru/wp-content/uploads/2023/04/2056121088.png)
Результаты подключения услуги «SEO с гарантией» для сайта стоматологии

Особенности, ограничения и доступные каналы

Настоящим Я даю свое полное согласие на получение электронных уведомлений (на указанные мой абонентский номер и адрес электронной почты), а также выражаю явное и полное согласие на сбор, хранение, обработку и передачу персональных данных, согласно положениям, изложенным в Политике конфиденциальности, расположенных по адресу: promopult.ru/rules.html?op=private, с которыми я ознакомился и принял.