
SEO: поиск и внутренняя оптимизация
Яндекс Wordstat: полное руководство по использованию сервиса
Как работать с ключевыми словами, операторами поиска и находить идеи для создания новых страниц
Для корректного управления индексацией интернет-магазина в поисковиках используется несколько инструментов, и один из них — robots.txt. Но в силу доступности и простоты инструмента многие вебмастера полагаются лишь на него, из-за чего в индекс попадают нежелательные страницы, которые потом приходится «вычищать». Выясняем, что представляет собой данный файл и что следует предпринять для правильной индексации сайта ecommerce.
Стандарт исключений для роботов (краулеров) — это файл в формате .txt. Он всегда называется «robots» и располагается в корневой папке сайта. В файле прописаны ограничения доступа для краулеров к данным на сервере.
Этот стандарт утвержден консорциумом Всемирной Паутины W3C в 1994 году. Его использование является добровольным (как для владельцев сайтов, так и для поисковиков).
С помощью robots.txt владельцы сайтов указывают роботам, какие файлы, страницы и каталоги сайта не должны индексироваться.
После того как поисковый робот начинает сессию обхода сайта, он в самом начале загружает содержимое robots.txt. Если файла нет или при обращении возвращается код, отличный от 200 OK, то робот будет индексировать все документы, расположенные в корневой и вложенных папках (при условии, что не использованы другие методы закрытия от индексации). Это чревато несколькими проблемами:
Инструкции поисковикам передаются с помощью директив. Полностью закрыть сайт от индексации можно с помощью двух строк в robots.txt (обычно это делают на этапе разработки сайта):
User-agent: *
Disallow: /
Символ * в строке User-agent: указывает, что директивы распространяются на всех роботов. Также можно прописать директивы для отдельных роботов (вместо * нужно указать название робота): Googlebot — главный индексирующий робот Google; YandexBot — робот Яндекса; Bingbot — робот Bing; YandexImages — робот Яндекс.Картинок и т. д.
Выполнение директив подчиняется ряду правил:
Полное описание правил и синтаксиса robots.txt есть на сайте robotstxt.org. При этом каждый поисковик имеет свои особенности и внутренние директивы. Например, для Яндекса необходимо прописывать директиву с указанием на главное зеркало сайта (остальные роботы эту директиву игнорируют):
Host: https://www.yoursite.ru
или
Host: https://yoursite.ru
До недавнего времени в Яндексе была уникальная директива Crawl-delay, которая указывала роботу на минимальный период времени (в секундах) между загрузками страниц. Но теперь она неактуальна, так как в Яндекс.Вебмастере появился функционал, позволяющий указать этот интервал.
Полное описание технических нюансов составления robots.txt для отдельных роботов представлено в справке Яндекса и Google.
В случае с информационными сайтами обычно не возникает проблем: скачали стандартный robots.txt с сайта поставщика CMS или форума разработчиков, подкорректировали в соответствии с особенностями сайта, разместили в корневой папке и забыли надолго или вообще навсегда.
С интернет-магазинами все сложнее:
С формальной точки зрения нет разницы, для какого сайта составлять robots.txt: директивы и правила неизменны хоть для блогов, хоть для интернет-магазинов. Но в виду большего разнообразия страниц и специфики работы CMS составление robots.txt для интернет-магазинов требует большего внимания со стороны вебмастера и в некоторых случаях опыта программирования на стороне сервера.
От индексации всегда закрываются системные файлы и админпанель. Папки с личной информацией пользователей и админпанель необходимо дополнительно защитить паролем.
Каждая CMS имеет уникальную файловую структуру, поэтому директивы robots.txt для закрытия служебных файлов будут отличаться. Приведем примеры директив для закрытия служебных файлов:
WordPress:
User-agent: *
Disallow: /wp-admin # админпанель
Disallow: /wp-includes # файлы движка
Disallow: /wp-content/plugins # установленные плагины
Disallow: /wp-content/cache # кешированные данные
Disallow: /wp-content/themes # темы
Opencart:
User-agent: *
Disallow: /admin # админпанель
Disallow: /catalog # данные интерфейса витрины
Disallow: /system # системные файлы
Disallow: /downloads # загрузки, связанные с товарами
Помимо системных файлов необходимо закрыть служебные страницы (директивы могут отличаться в зависимости от CMS и структуры URL конкретного сайта):
Также закрываются URL, которые включают идентификаторы источников переходов:
Также иногда закрывается доступ для роботов, которые создают дополнительную нагрузку на сервер (особенно актуально для крупных интернет-магазинов):
В интернете можно найти огромные списки с нежелательными роботами, но прежде чем создавать для каких-то из них запрещающие директивы, убедитесь, что не потеряете часть трафика.
После создания файла с директивами обязательно проверьте его валидность в Яндекс.Вебмастере и Google Search Console. Если ошибок нет, разместите robots.txt в корень сайта (паролем не защищайте!).
Если на вашем сайте несколько поддоменов вида msk.site.ru, то все файлы домена и поддоменов лежат в одной корневой папке. А значит, по умолчанию поисковый робот будет искать и принимать во внимание директивы только в одном файле с названием «robots.txt».
А если нужно отдавать разные директивы для домена верхнего уровня и поддоменов? Для этого создайте дополнительный файл с названием robots-subdomains.txt и разместите его в корне сайта.
Для веб-сервера Apache нужно дописать такие строки в файл .htaccess:
RewriteCond %{HTTP_HOST} ^subdomain.site.ru$
RewriteRule ^robots.txt$ /robots-subdomains.txt [L]
Теперь при обращении к поддоменам роботам будет отдаваться содержимое robots-subdomains.txt.
Самый большой недостаток robots.txt — его необязательный характер. Google пишет, что директивы носят рекомендательный характер (настройки robots.txt являются указаниями, а не прямыми командами). Кроме того, если на закрытую страницу ведут ссылки с внешних источников, роботы перейдут по ним и проиндексируют страницу.
Продемонстрируем это на практике. На сайте интернет-магазина обуви есть страница сравнения товаров. В файле robots.txt она закрыта от индексации:

Но если поискать эту страницу в поиске Google, то увидим следующую картину:
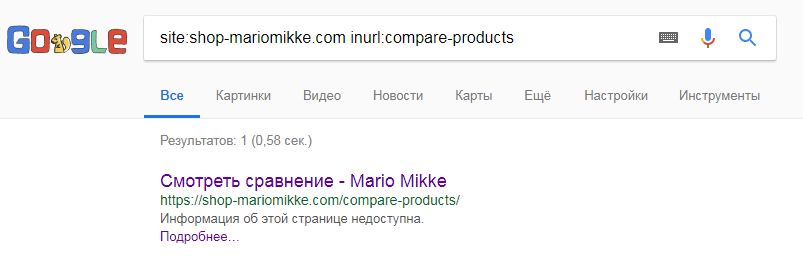
Страница проиндексирована, ссылка на нее из поиска работает, но описания нет. Такая ситуация возникает как раз в случаях, когда робот индексирует закрытые в robots.txt страницы.
Чтобы удалить страницу из индекса, придется сначала открыть доступ к ней роботу через robots.txt, дождаться полноценной индексации, а потом закрыть с помощью мета-тега robots со значениями “noindex,nofollow”. Это более надежный вариант.
Что характерно, этой же страницы в поиске Яндекса нет (считается, что Яндекс более строго следует директивам в robots.txt, чем Google):
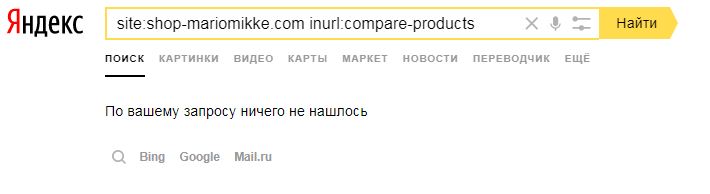
Для того чтобы наверняка скрыть от роботов важные страницы (админпанель, служебные папки и файлы, где хранятся личные данные пользователей), обязательно используйте защиту паролем.
Также используйте возможности мета-тега robots — он позволяет наверняка закрыть доступ поисковикам к страницам. Кроме того, с его помощью можно позволить роботам переходить по ссылкам без индексации содержимого сайта, или наоборот (значения “noindex,follow” и “index,nofollow” соответственно).
Итак, корректная индексация интернет-магазина зависит не только от директив в robots.txt. Есть масса нюансов, которые стоит учитывать, чтобы в индекс попали правильные страницы, а не «мусор» или конфиденциальные данные. Для настройки индексации и проверки других важных параметров сайта подключите в PromoPult обновленный модуль SEO — опытные специалисты системы проанализируют ваш ресурс и внесут корректировки, если в этом будет необходимость.
Как работать с ключевыми словами, операторами поиска и находить идеи для создания новых страниц

Задачи и инструменты для настройки динамического контента

Как управлять поисковыми роботами: задайте порядок и периодичность обхода

— Мы только спросить: нужен трафик и лиды из поиска Яндекса и Google?

Подключите бесплатное продвижение на 2 недели и получите взрывной рост позиций в Яндексе и Google, целевой трафик и продажи.

Настоящим Я даю свое полное согласие на получение электронных уведомлений (на указанные мой абонентский номер и адрес электронной почты), а также выражаю явное и полное согласие на сбор, хранение, обработку и передачу персональных данных, согласно положениям, изложенным в Политике конфиденциальности, расположенных по адресу: promopult.ru/rules.html?op=private, с которыми я ознакомился и принял.