
Growth Hacking: повышение конверсии
Как создать лендинг: пошаговая инструкция
Подготовка, основные блоки, инструменты для верстки и повышения конверсии
Емкий сценарий работы с семантическим ядром
Дмитрий Шевцов (semantist.ru), спикер прошедшей недавно конференции CyberMarketing-2018, рассказывает, как собрать семантическое ядро и довести его до ТЗ на доработку страниц. Формула «3*3» увязывает все действия, необходимые для работы с семантикой на проекте.
С помощью глубокого изучения семантики можно реанимировать старый проект и получить прирост трафика более чем в 2 раза, без накруток. Можно сократить расход на рекламу более чем в 2 раза. Дать системный рост трафика для медийного портала. С нуля создать правильный интернет-магазин под SEO трафик.
Когда меня впервые попросили написать мануал «Как собрать семантическое ядро», мне это показалась плохой идеей. Я знаю больше пяти разных ситуаций, когда к нам приходят за семантикой. Например:
Однако, проанализировав опыт более 100 проектов, я смог выделить базовые этапы и процедуры. Удалось свести их до 3 этапов в каждом по 3 шага.
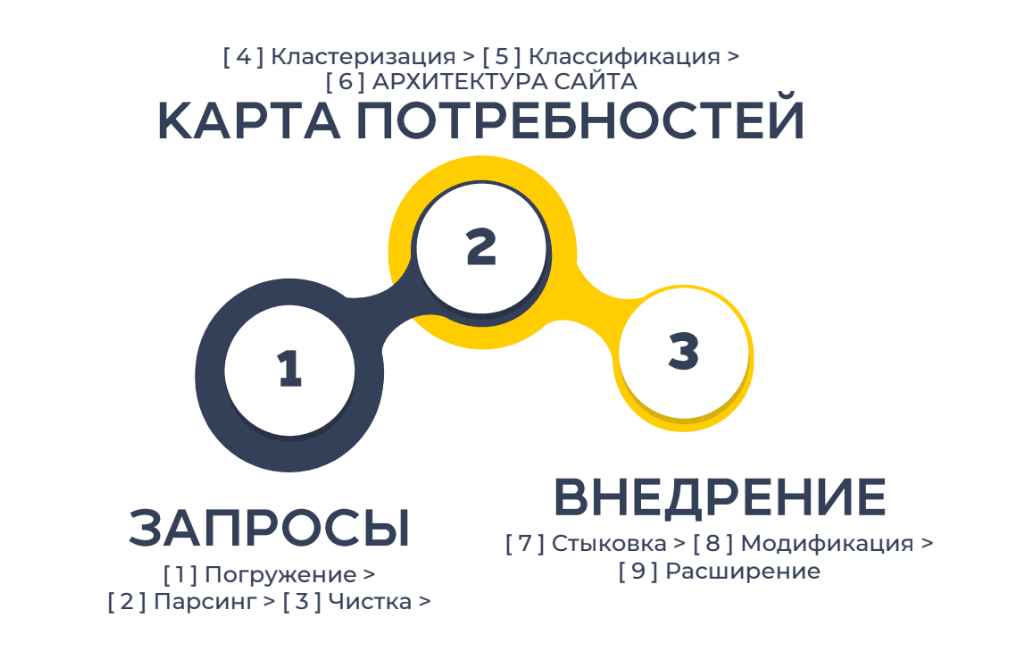
Весь процесс сбора семантики можно разделить на 3 этапа:
На первом этапе нужно получить базу запросов для кластеризации. Для этого запросы нужно собрать и почистить. Чистить на этом этапе нужно не сильно, почему — расскажу подробнее на 3 шаге.
Зачем погружаться в тематику? Например, чтобы работать с семантикой сайта инструментов для маникюра, нужно знать что такое бор, корундовый наконечник, как маркируются инструменты вращения. Без этого артикулы и экспертные термины будут не добавлены на старте или удалены в конце при чистке.
Этот этап пропускают при скоростном сборе семантики за несколько дней. Если семантист не овладеет темой, то он совершит множество ошибок, не подозревая об этом. Опасность в том, что проверить такие ошибки может только эксперт в тематике.
Критически важно изучение терминологии в профессиональных тематиках, автозапчастях, специализированных инструментах и товарах премиум класса. Например: «карат ask.20» — это сейф, «корунд В5» — это бор диаметром 4,40 мм со средней абразивностью и так далее.
Самый простой метод систематизировать изучение:
В процессе составления сводной таблицы для всех незнакомых терминов на сайтах находим объяснение в википедии или технических справочниках. В сложных тематиках поможет только клиент.
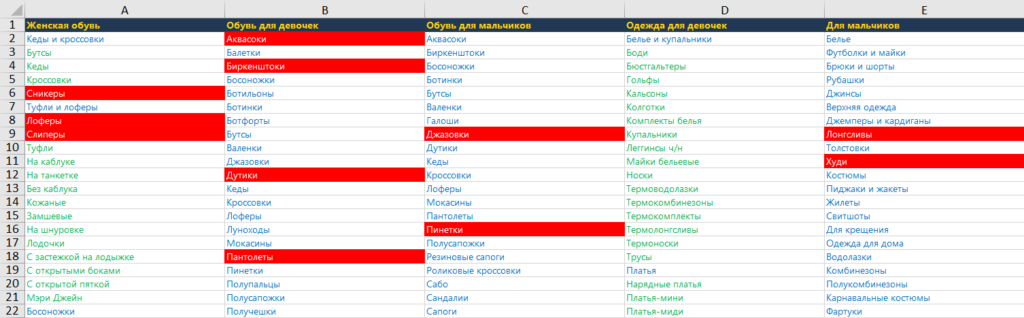
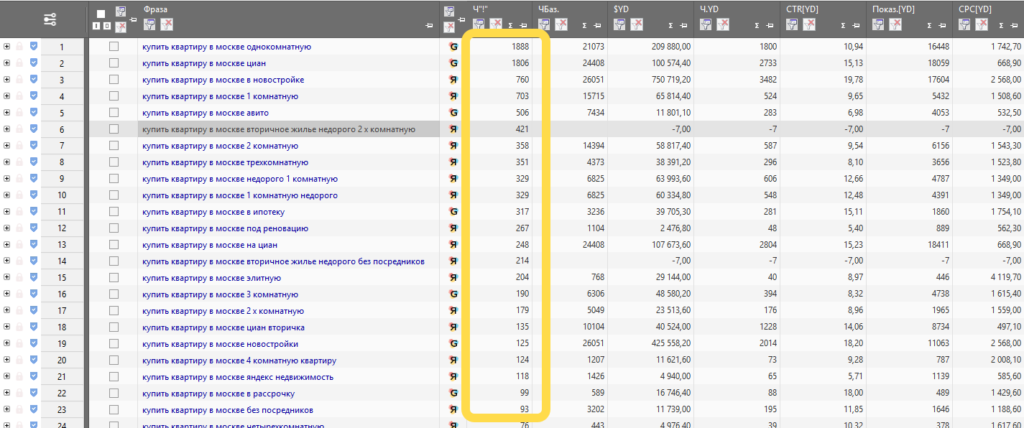
Например, на картинке фрагмент сбора базовых запросов для тематики одежды. Красным выделены термины, которые требуется проверить. Сникеры, лоферы, слиперы, биркенштоки, аквасоки, лонгсливы, худи. Возможно, часть терминов — сленговые или вовсе не целевые. Проверяем их и включаем в работу или отбрасываем.
Дополнительно можно использовать платные сервисы видимости. Эти сервисы позволяют на запрос «кеды» получить сотни понятий и терминов (аналогично правой колонке WordStat).
Результат этапа: овладение базовой терминологией тематики, таблица базовых фраз для последующей работы.
Обновленный модуль SEO: для тех, кто не хочет тонуть в рутине. Все инструменты для улучшения качества сайта и поискового продвижения. Занимайтесь стратегией, мы сделаем все остальное!
На этом шаге из базовых запросов нужно получить большую базу ключевых фраз и перейти к чистке. Если на первом шаге нужна внимательность специалиста, то тут главное — технологические возможности.
Собирать фразы лучше в KeyCollector, он подходит даже для крупных семантик на 1 миллиона запросов. Однако для постоянной работы с крупными ядрами нужно провести тюнинг для KeyCollector.

Тюнинг трех слабых мест:
KeyCollector готов, и дальше начинаем парсить. Подключаем правильные источники на правильных этапах. Я разделяю источники на 2 типа — парсинг в ширину и в глубину.
Источников ключевых фраз много, количество их постоянно растет.
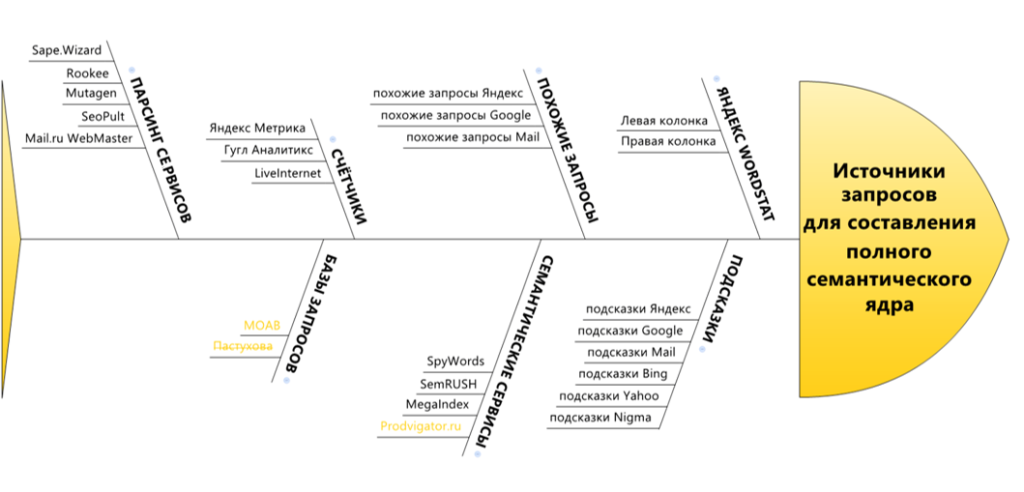

Сервисы парсинга в ширину дают не много, но очень ценных фраз (чаще синонимов). Например на слово «кеды» мы получаем «кроссовки», «бутсы» и т.д. Парсинг в глубину из слова «кеды» даст «купить кеды», «кеды мужские», «зимние кеды».
Инструменты для ширины важно применять на первых этапах (для погружения в тематику).
Пример: правая колонка WordStat на слово «кеды» даёт «спортивная обувь», «хип хоп одежда», «конверс купить», «nike wmns».
Яндекс подскажет «с кеды ищут» такие запросы «кроссовки», «converse», «слипоны», «найк», «вансы», «vans», «конверсы», «кроссовки найк», «мокасины», «группа кеды».
Google — «кеды высокие», «кеды женские», «кеды википедия», «кеды адидас», «кеды история».
В глубину хорошо парсит левая колонка WordStat: «кеды на танкетке», «кеды Москва», «кожаные кеды».
Умный поиск запроса SpyWords даёт углубление и в наши «кеды» хорошо добавляет бренды и типы «кеды гуччи», «кеды рибок», «детские кеды для мальчиков», «кеды xiaomi».
Максимальную глубину дают базы запросов MOAB, Пастухов. Их хорошо использовать, когда уже есть все возможные исходные синонимы. Т.к. не зная всех вариаций мы не вытащим фразы с латинским корнем «nike», по маске *найк*.
Результат этапа: база запросов.
Сбор поисковых подсказок системы PromoPult: глубина до третьего уровня. Помощь в сборе поисковых подсказок в Яндексе и Google, а также YouTube.
На этапе чистки важно не переусердствовать и удалить только те фразы которые 100% не войдут в финальное ядро.
Со стоп-словами нужно поступать аккуратно. Например, популярное слово «фото» является плюс словом для записи на консультацию к врачу.
В KeyCollector этот инструмент продолжает развиваться и на текущий момент — это комбайн для поиска стоп-слов.
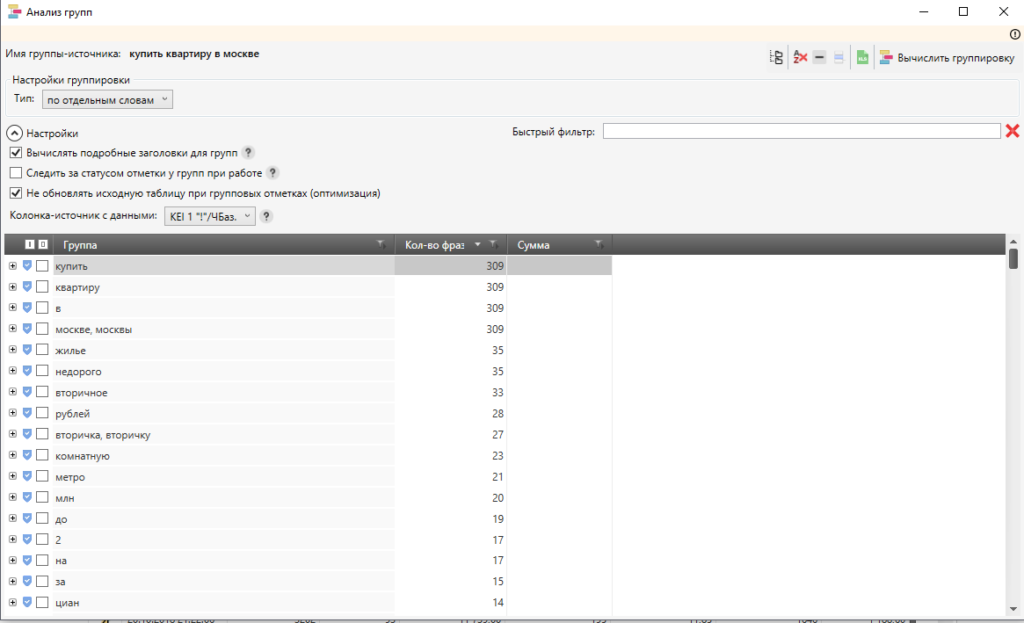
Простой и эффективный способ очистить большую семантику на 100 000 фраз от 70% нулевок — это сбор частоты «!» по WordStat. Так как оптимизация под запросы, запрашиваемые менее 1 раза в месяц, не целесообразна. Способ особенно эффективен в тематиках с одеждой, электроникой и любыми популярными товарами, в информационных порталах.
Этот способ не подходит для низкочастотных нишевых тематик, где каждый запрос на вес золота. Например, если вы занимаетесь продажей коммерческой недвижимости, конкуренты оптимизируются даже под один переход в месяц по адресу офиса.
Результат этапа: чистая база фраз для кластеризации.
Этап позволяет выделить группы фраз и получить каркас из потребностей в нише.

Популярные кластеризаторы в основном платные, бесплатные кластеризаторы не рекомендую применять для больших и сложных проектов, т.к. больше будет переделок чем ускорения процесса.
Когда семантическое ядро у вас — более 10 000 фраз, обычно начинаются проблемы с проверкой частоты, SERP, позиций.
Результат этапа: кластеризованная база.
Классификация необходима для распределения по разделам ваших кластеров. Кластеризация выдаёт линейную структуру — без разбора полотно из 5000 страниц бесполезно. Из разделов можно потом построить MindMap.
Классификация в Excel выглядит примерно так:
Результат этапа: черновик меню — на совмещение с бизнесом.
На этом этапе важно произвести стыковку всего, что бывает, и реальными возможностями бизнеса. Работа проводится с привлечением заказчика.
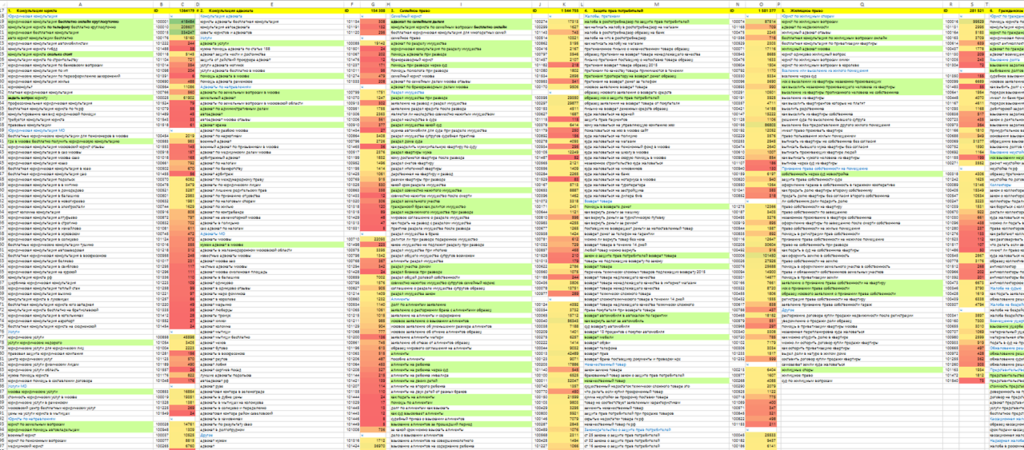
Чтобы в миллионе фраз увидеть золотые запросы, используют методику скоринга. Она позволяет автоматизировать процесс предварительной оценки и снизить влияние субъективного видения эксперта на результат.
В процессе скоринга каждый запрос получает суммарный балл по всем возможным характеристикам (CPC Директа и AdWords, параметры из сервисов аналитики, конкуренцию). Балл получается в результате вычислений полинома, это формула ранжирования. Технологию подробно раскрывает Дмитрий Иванов в своих докладах и статьях.
Результат этапа: Меню (разделы подразделы), кластеры.
Этап не актуален для новых проектов. Для нового проекта весь третий этап — это создание новых посадочных страниц. Для старого же проекта это — важнейший вопрос привязки семантики.
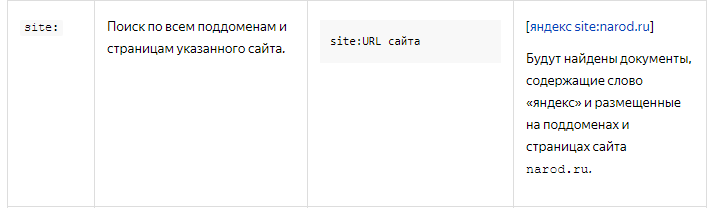
Мы чаще всего используем для стыковки релевантные страницы. Определить их можно в KeyCollector. В реальности (под капотом) программа делает запрос в поисковик вида: site:yandex.ru [помощь документный оператор site], по сути, задавая вопрос Яндексу, какая страница точнее всего отвечает на запрос.
От редакции: определить релевантные страницы также можно с помощью SEO-модуля системы PromoPult. Здесь страницы определяются не под отдельные запросы, а под целые кластеры, что намного удобней в плане организации работы с семантикой. Если система не найдет релевантной страницы на сайте, она предложит создать ее.
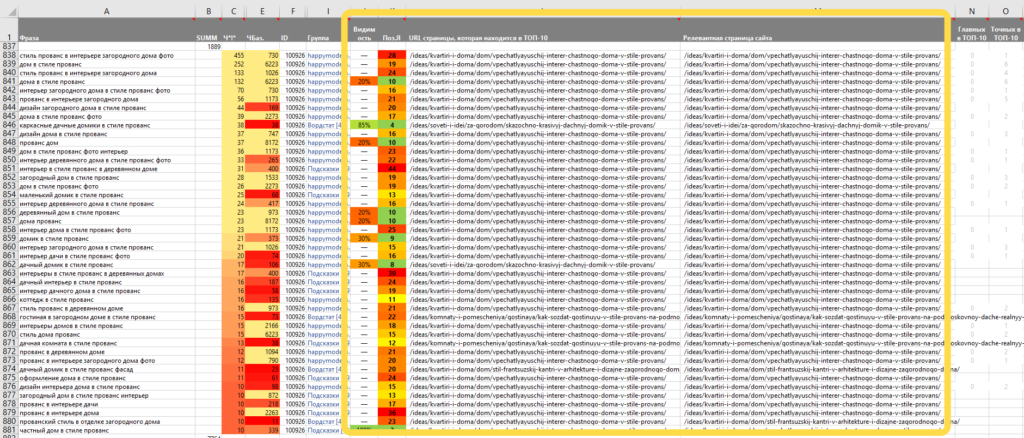
Группа 1 (страницы в ТОП-10) — сохраняем эти страницы и мониторим, пока они не выпадут из топа, тогда переносим их в группу 2.
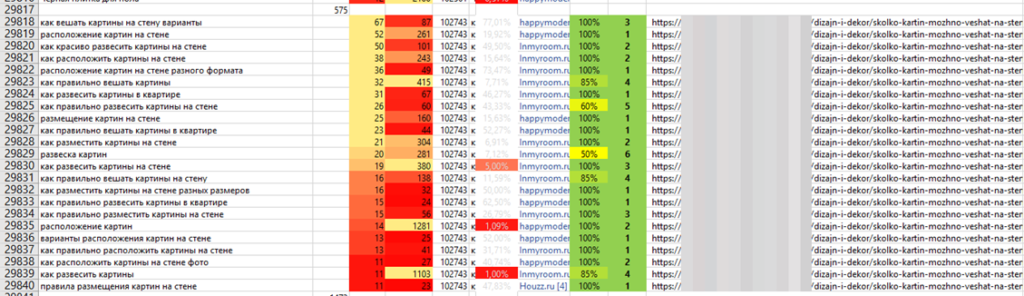
Группа 2 (страницы ниже ТОП-10) — для этапа МОДИФИКАЦИИ, они требуют доработки.
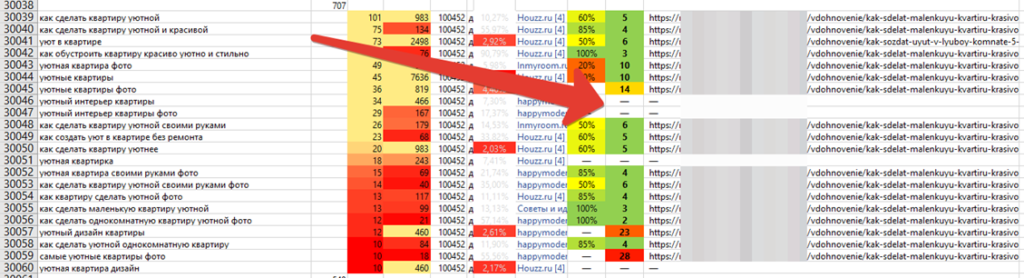
Группа 3 (страницы нужно создавать) — создаём посадочные по всем правилам SEO-оптимизации, пишем ТЗ на тексты, если в этом есть необходимость. В сравнении с группой 2 — сокращается время на поиск критериев, по которым страница не дотягивает. Создать новый текст с чистого листа стоит дешевле.
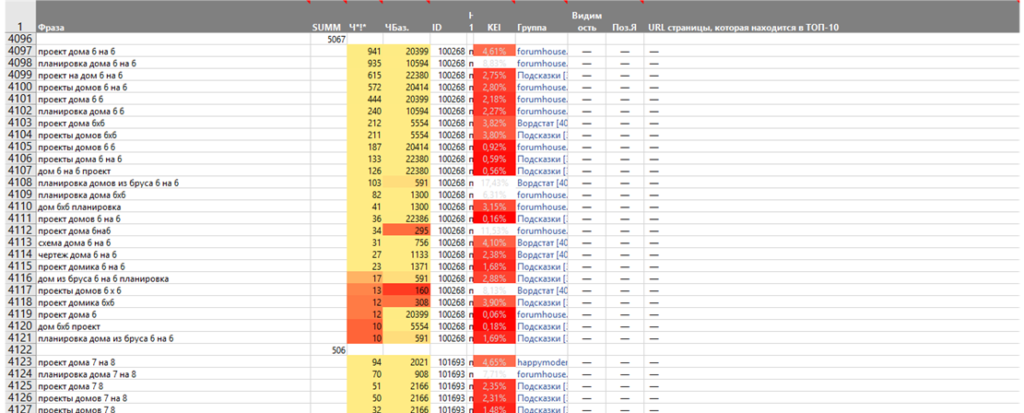
Результат этапа: 3 группы запросов.
На этом этапе нужно разобраться, почему страница не продвинута. Первый шаг — визуально оценить страницу. Если тут всё в порядке, значит, нужна аналитика.
Самый простой способ доработать под ТОП-10: перейти по запросам из кластера и оценить страницы конкурентов системно. Оценивать лучше в таблице: по функционалу, коммерческим факторам, текстовым и юзабилити.
После того как установлено направление доработки, формируются технические задания. Чаще всего на тексты и функционал. Если есть проблемы с юзабилити и коммерческими факторами, потребуется большое системное ТЗ разработчикам сайта.
Результат этапа: список страниц с ТЗ на доработку.
Для нового проекта — этот шаг единственный. Здесь мы создаем страницы по SEO-правилам.
Пишем ТЗ на тексты, пишем тексты, прописываем ЧПУ, формируем длинные TITLE из кластеров, составляем H1, верстаем и оптимизируем код страницы, прописываем ALT картинкам и т. д.
Для маркетплейсов и интернет-магазинов — где количество страниц высоко — актуален вопрос автоматизации создания посадочных страниц. В H1 можно брать самый частотный запрос в кластере. Title генерировать из нескольких фраз кластера или использовать любые актуальные на сегодня алгоритмы генерации TITLE.
Критичный вопрос автоматизации — качество выборок. Даже если вы прикрутили умный поиск по сайту и движок Sphinx, вы всё равно сталкиваетесь с проблемой нерелевантных товаров. Описание у товаров не всегда качественно и релевантно запросу.
Другими словами, если в базе описаний товары типа «майка женская с цветами» названы «майка женская с цветочным принтом», то могут быть такие выборки (пример из реального проекта):
Поиск по запросу «майка женская с цветами»:
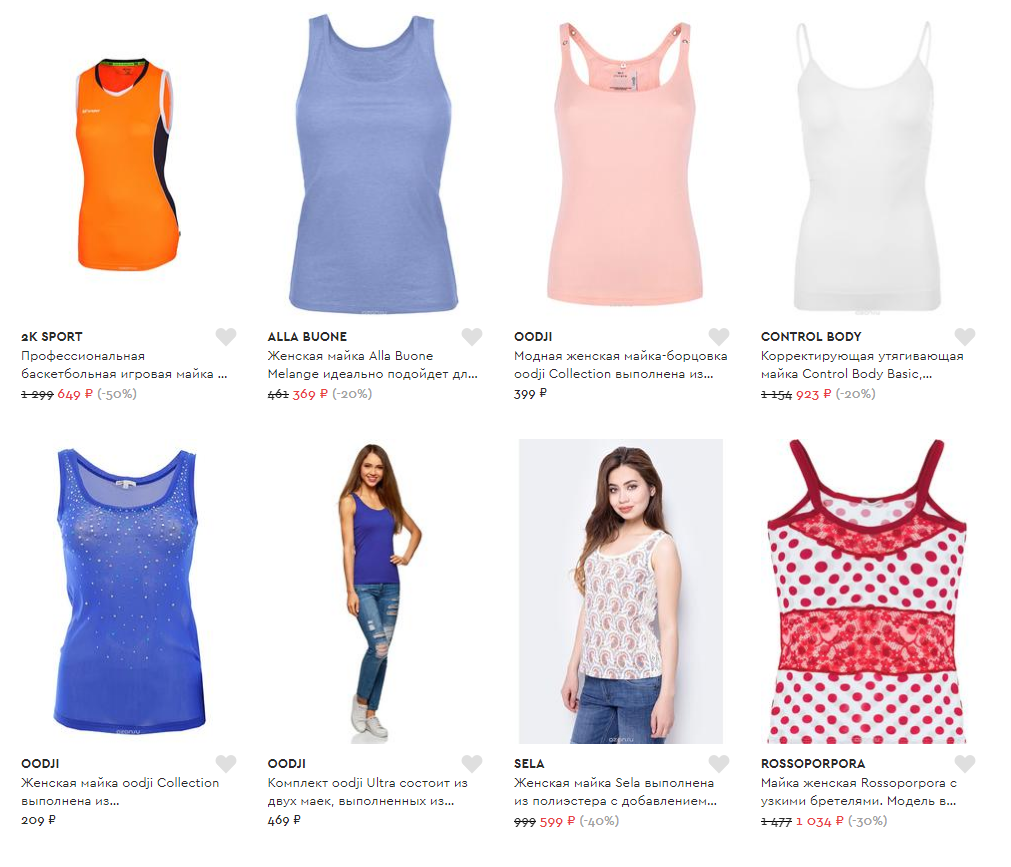
Поиск по запросу «майка женская с цветочным принтом»:
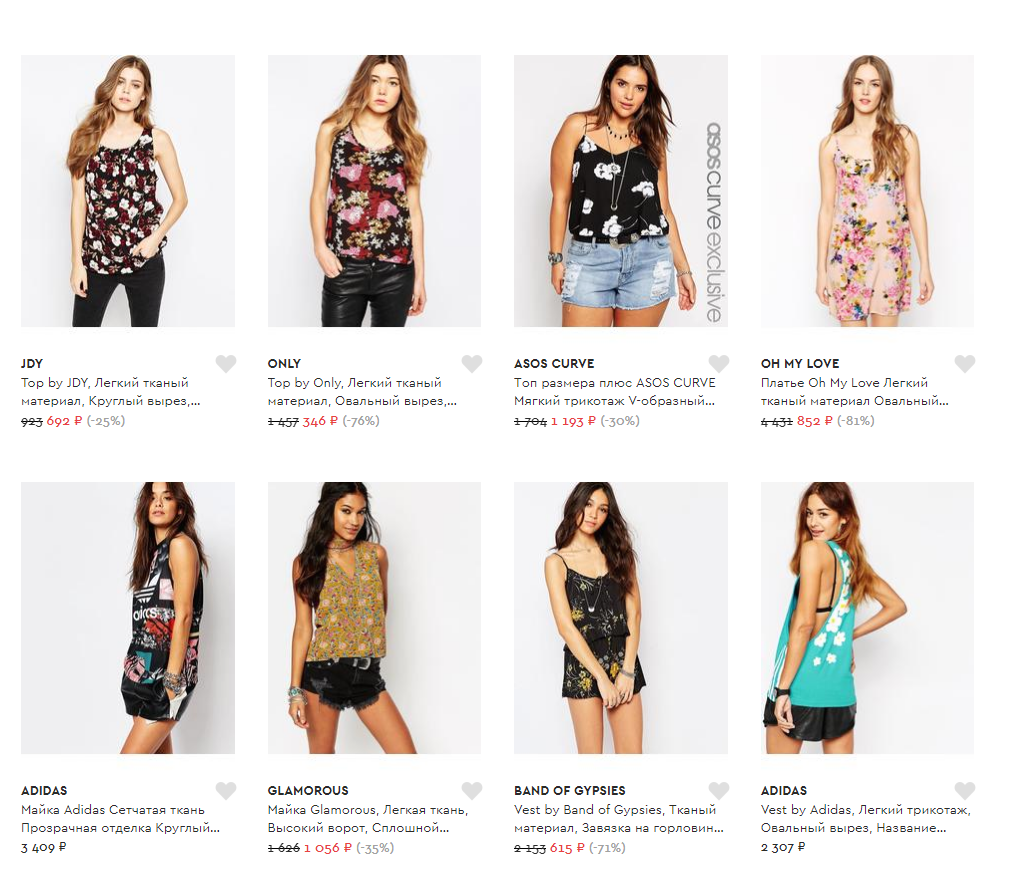
Найти лучший вариант запроса поможет проверка не одной фразы из кластера, а нескольких — с просмотром результатов.
Результат этапа: список ТЗ на создание новых страниц.
Когда семантика внедряется или уже внедрена, нужно цикличное повторение 7 и 8 пунктов для «дожима» страниц. Т.е. вы снимаете позиции и перемещаете группы из 2 и 3 раздела в раздел 1 (когда они достигли ТОПа).
Выполните все 3 этапа по 3 шага и вы получите самую полную семантику под именно ваш бизнес. Старый проект по нашему опыту растет минимум в 2 раза. Рост нового магазина на нашем опыте с нуля до 10000 в сутки происходил за 9 месяцев.
Подготовка, основные блоки, инструменты для верстки и повышения конверсии
![Как быстро собрать поисковые подсказки из Яндекса, Google и YouTube [инструкция PromoPult]](https://blog.promopult.ru/wp-content/uploads/2018/05/StockSnap_L7X3V4PRUI_600x360.png)

Шпаргалка для тех, кто хочет разобраться в основах внутреннего SEO и сэкономить время

Настоящим Я даю свое полное согласие на получение электронных уведомлений (на указанные мой абонентский номер и адрес электронной почты), а также выражаю явное и полное согласие на сбор, хранение, обработку и передачу персональных данных, согласно положениям, изложенным в Политике конфиденциальности, расположенных по адресу: promopult.ru/rules.html?op=private, с которыми я ознакомился и принял.